Concatenate, Compress, Cache
04 Mar 2015This post is cross-posted on the Octo Technology blog
When trying to optimize the performance of your website, there are three main elements that should be on your top priority list. Three very easy-to-implement steps that can have a great impact on your website load time.
These three methods are named concatenation, compression and cache. I've already talked about them in a previous talk (in French), but we'll now cover them in full detail.
Concatenate
The main goal of concatenation is to merge several files of the same type in one final file. Doing so will allow us to transfer less files over the wire. CSS and JavaScript files are the one that yields the better results.
The nature of downloading assets itself makes your browser pay some costs on every request, and in the end all those lost milliseconds adds up. Let's have a look at the different costs we're paying:
TCP Slow start
TCP is the underlying protocol used by HTTP. It uses a mechanism known as slow-start to get to the optimal transfer speed. To do so, it must do a few round trips between the client and the server, sending more and more data, until some are dropped, in order to get the maximum possible sending/receiving throughput.
If we send a lot of small files, the mechanism never has time to reach the optimal speed, and must start its round trips again on the next file. By grouping files together in one bigger file, the cost of calculating the max speed is only paid once and the remaining of the file can be downloaded at full speed.
Note that maintaining Keep-Alive connections on your server can let you reuse a previous connection, and thus only pay this cost once. Unfortunately, activating Keep-Alive on an Apache server will also limit the number of parallel connection your server can handle.
SSL
Similarly, the same kind of cost is paid when serving the site using https. In order to prove that both client and server really are who they claiming to be, an exchange of keys is done through a secure handshake. Once again, the cost of the handshake is paid on each downloaded asset. Putting all your files in one lets you pay the cost only one.
Parallel connections
Finally, the last limiting factor is purely in the client browser. Each browser keeps track of a max number of parallel connections it can maintain opened to any given server. The HTTP spec officially set this number to 2, but in the real world browsers usually have a higher value, ranging from 8 to 12.
This means that if you ask your browser to download 5 stylesheets, 5 scripts and 10 images, it will only launch the download of the 12 first elements. The 13th asset download will only be started once one of the 12th first will be finished. Once again, grouping your files together will allow you to have more opened channels that will be used to download important assets of your page.
CSS and JavaScript files can be very easily concatenated. You only have to create one final file that simply contains the content of all your initial files. Your build process can easily take care of that, but a very simple solution can be written in a few lines:
cat ./src/*.css > ./dist/styles.css
cat ./js/*.js > ./dist/scripts.js
Please note that merging image files is also possible (and is named CSS Spriting) but is out of the scope of this article.
Compression
Now that we've reduced the number of files, the next logical step is to make this files smaller, so they can be downloaded faster.
Fortunately, the web has a magic word named Gzip that will reduce the size of each textual asset by an average of 66%.
The good news is that most of the assets that we use to build a website are actually made from text. Main bricks like HTML, CSS and JS of course but also output from your API (JSON and XML). A lot of other format are in fact XML in disguise, like RSS, web fonts or SVG images.
It is rare enough to be pointed out, but Gzip is perfectly supported by all major browsers and servers (even as far back as IE5.5). There are absolutely no reason to not use it.
If a browser does support Gzip, it will send an Accept-Encoding: gzip header to the server. If the server find this header in the request, it will compress the file on the fly before returning it to the client. It will also add the Content-Encoding: gzip header, and the browser will uncompress once received.
The main point here is to have a smaller file moving across the wire. Server and client will respectively compress and decompress the data, but the added overhead is negligible on any machine built in the last decade. Having much less data to transfer over the wire will give you tremendous speed improvements.
Gzip compression modules are already available on all kind of servers, all you have to do is enable them. You simply configure which kind of files must be compressed, referencing them by their mimetype. You'll find below a few examples on the most common servers:
Apache
<IfModule mod_deflate.c>
<IfModule mod_filter.c>
AddOutputFilterByType DEFLATE "application/javascript" "application/json" \
"text/css" "text/html" "text/xml" [...]
</IfModule>
</IfModule>
Lighttpd
server.modules += ( "mod_compress" )
compress.filetype = ("application/javascript", "application/json", \
"text/css", "text/html", "text/xml", [...] )
Nginx
gzip on;
gzip_comp_level 6;
gzip_types application/javascript application/json text/css text/html text/xml
[...];
Enabling Gzip is really easy to set and it greatly improves loading time. You do not have to change anything on the served files, all the configuration occurs in the servers.
Minification
If you want to go even farther, you can invest on minifying your assets. Once again, HTML, CSS and JavaScript are the best languages for minification.
Minification is a process that will rewrite all your assets in a lighter version, using less characters, and thus being smaller to download. In essence, it will remove comments and new lines, but language-specific minification tool can also rename variable in your JS to shorter ones, group CSS selectors or remove useless HTML attributes.
Adding a minification tool to your build process is more complex than enabling Gzip and yields less impressive results. That's why we highly recommend that you do not try to tackle it until you've enabled Gzip.
Cache
Now that we've limited the number of files and slimmed them down, the next step is to download them as seldom as possible.
The main idea here is that there is no need to download something that your user already has on its hard drive.
We're going to start by explaining how the HTTP cache mechanism works. This is an area that is usually not very well understood by developers, so we'll try to make it clearer. The main element is that there are two very different parts in the HTTP cache : freshness and validation.
Freshness
Freshness is best understood as a "best-before" date for your assets. When downloading an asset, the server send it with a header telling us until when the asset will be considered fresh.
If the client needs the same asset again, it first checks the freshness of the one in its cache. If it is still fresh, it does not start a request to the server and directly use it. Nothing can be faster than that, because there is absolutely no network involved.
On the other hand, if the freshness date is overdue, the browser will start a new connection to get the latest version.
In HTTP 1.0, the server returns an Expires header including the max freshness date. For example: Expires: Thu, 04 May 2015 20:00:00 GMT. This means that when the client asks for the same asset again before May 4th 2015 at 8pm, it will simply read it from its cache.
This header has a major flaw in the fact that dates are absolutely fixed and thus the cache of all your clients will be invalidated at the same time. On May 4th, all your clients will request the new version of your asset at the same time and your server might not be able to cope with all those connections.
To limit this effect and give a bit more flexibility in handling the cache, HTTP 1.1 introduced a new header. Cache-Control accepts several arguments, but the one we're interested in here is max-age. It lets you define a cache duration in seconds.
Your server can now answer with a Cache-Control: max-age=3600 header. It tells the client that the asset will still be fresh for the next minute (3600 seconds). By using this header, you can space your calls over a longer period.
Validation
The second part of caching is named validation. Let's imagine that our asset is no longer fresh. We'll need to grab the latest version on the server. But it is perfectly possible that the asset on the server hasn't been updated since the last time the client fetched it. In that case it would be useless to download it all over again.
That's when the validation kicks in. If the asset on the client is identical than the one on the server, the client can keep its local version. If the two assets are different, then the client downloads the new version from the server.
How does it work ? When the client got the asset for the first time, it fetched it along with a Last-Modified header. For example Last-Modified: Mon, 04 May 2015 02:28:12 GMT. This means that the next time the client will make a request to get the same asset, it will send this date in the If-Modified-Since request header: If-Modified-Since: Mon, 04 May 2015 02:28:12 GMT.
The server will then compare the sent date with the one it has on its side. If the two dates matches, it will return a 304 Not Modified status, telling the client that the content has not changed. The client in turn will use its local version, and we avoided transmitting useless data over the wire.
On the other hand, if the server file is newer than the client file, the server will with a 200 OK alongside the new content. That way, the client will now download and use the new version.
By correctly using the validation mechanism, we avoid downloading a content we already have.
In both cases, the server sends the freshness information again.
The HTTP spec allows us to choose between two couples of headers. We can either use the Last-Modified / If-Modified-Since headers, as we just saw, or use ETags.
An ETag is a unique identifier hash for a file. Whenever a file is updated, its ETag will change too. For example, on the first call the server will return an ETag: "3e86-410-3596fbbc" header. When the client will ask for this asset again, it will send an If-None-Match: "3e86-410-3596fbbc" header. The server will in turn compare the two ETags and either return a 304 Not Modified if they are the same, or a 200 OK with the new content if they are different.
Last-Modified and ETag use very similar mechanism, but we advise you to use Last-Modified over ETag.
Indeed, the HTTP spec tells us that in the case of receiving both a Last-Modified and an ETag, the client should use the Last-Modified. In addition, most servers generate their ETag using the inode of the file on disk, so anytime the file is changed, it is reflected in its ETag.
Unfortunately, this can cause issues if you have several servers serving the same content behind a load-balancer. Each server will have a copy of your files, but on different filesystems which will result on different inodes, thus different ETags for the same file. And your whole validation system will not work as soon as your user gets redirected to a new server.
Note that nginx does not have this issue as it does not use the inode when generating ETags. If using Apache, you can fix it with the FileETag MTime Size option, or with etag.use-inode = "disable" under lighttpd.
Summary
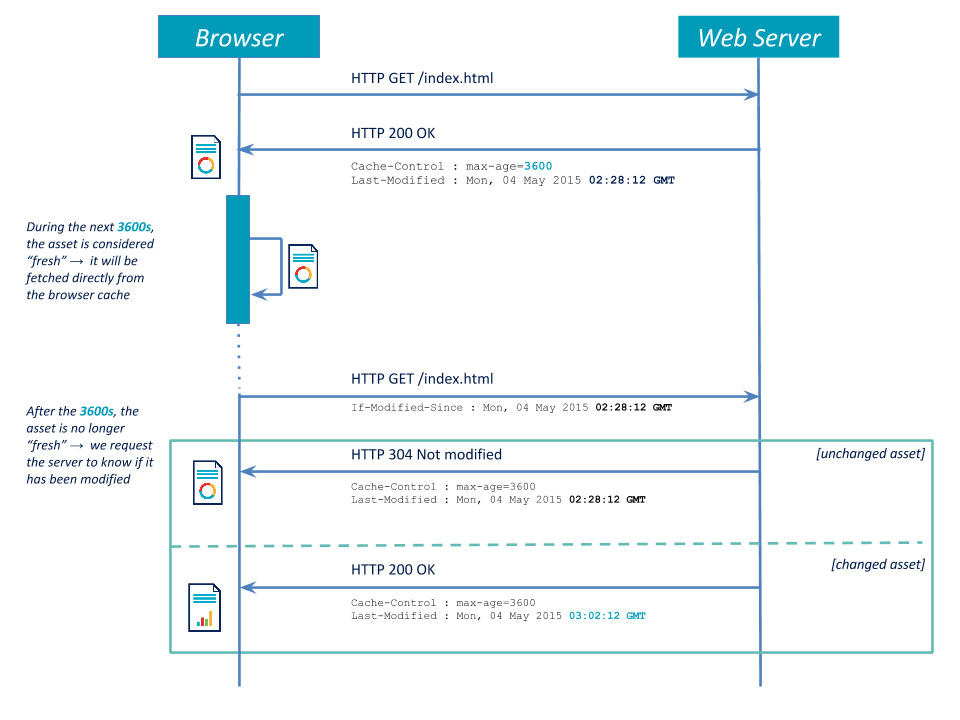
- The client makes a first request to get an asset. It gets a
Cache-Control: max-ageheader indicating freshness, and aLast-Modifiedfor validation. - If requesting the same asset again while this one is still fresh, no network connection is made and the asset is directly read from the local disk.
- If requesting the same asset after its freshness date, the client makes a call to the server, sending along an
If-Modified-Sinceheader. - If the file on the server has a modification date equal to the one sent, it then returns with a
304 Not Modified. - If the file has been modified since the last time, the server answers with a
200 OKalongside the new content. - In both cases, the server returns a new
Cache-ControlandLast-Modified.
Cache invalidation
Caching is a hard to tame beast, and we all know that:
There are two hard things in Computer Science: cache invalidation and naming things.
And that's right, invalidating the cache of our clients when we need to push a modification is extremely difficult. It's actually so difficult that we're not going to do it at all.
Browsers cache stuff according to their URL. So if we need to update some content, we only need to change its URL. URLs are cheap, we have them in unlimited quantity, we can create as many as we need. We can add a version number, a timestamp or a hash to our original filename and generate a whole new URL.
For example : style-c9b5fd6520f5ab77dd823b1b2c81ff9c461b1374.css instead of style.css.
By putting a very long cache period on these assets (1 year is the official max the spec allows), it's like having them in cache forever. We just need to put a shorter cache on the file that reference them (usually the HTML file).
That way, when pushing to production a modification to a stylesheet or to a script, we just have to update the references to those files in our HTML sources so our clients can download the new content. The cache period on HTML files is much shorter, so updates pushed to production will be quickly taken into account by clients.
Old content will stay in our clients cache, but this does not matter because we will never request them again and unused items in cache are regularly erased.
This technique is actually quite close to the ETag we saw earlier, with one big difference. Here, we can choose when we want to invalidate our client cache.
In the end, we use a mix of both techniques to handle and optimal caching strategy.
When the URL of an element is important (like HTML pages, or API endpoints), we set a short freshness period (in seconds or minutes, depending on the average update rate). This way we're sure that our clients will have the new pushed version quickly after we deployed it, while still limiting the number of requests the server must handle.
When the url of an element is not important (like CSS, JavaScript or image files), we'll use the maximum freshness duration (1 year). This will let the client keep the element in its cache forever, and avoid requesting the server ever again for this asset. Whenever we update the file on our end, we'll generate a new URL for it and simply update the reference to it in the HTML source.
Conclusion
We saw how three very simple actions could greatly lower the total number of files to download, make them smaller and download them less often.
Automatic file concatenation should be integrated into your build process, so you can keep your development environment clean. Gzip compression only needs a few configuration switches on your servers. Setting an optimal caching strategy will require some work both on the build process and on the servers.
All those modifications are quite cheap to put in place and are not tied to any back-end or front-end specific language, they can be applied whatever your technical stack is. There is no reason why you couldn't deploy them today.
Want to add something ? Feel free to get in touch on Twitter : @pixelastic