Marvel Super-Search
01 Jun 2016Last December I discovered that Marvel had an API. Yes, that's right, Marvel, the publisher of all the comics I used to read. I'm a developer, but I'm also an avid consumer of APIs and love to build things with all the available data.
Since I joined Algolia, I'm always looking for nice datasets to build demos with, and to battle test our instantsearch.js library. While Algolia lets you search in any kind of data (as long as you can convert it to JSON), fiddling with a dataset full of superheroes is way funnier than any other dataset.
You can see the full demo here
So I started registering to the Marvel developer program to get an API key and started pulling some data. Or actually that was my original plan, but the developer website was buggy at that time and I could not register at all.
At first I was disappointed because I really wanted to index all these characters and superpowers, but I wasn't going to let that bring me down. I started rolling up my sleeves and went on the hunt for another interesting source of data.
Wikipedia
I obviously quickly ended up on the Wikipedia, where I could find a serie of pages listing all the heroes and villains of the Marvel universe (or actually, universes). I wrote a small node script using x-ray to get the list of names and matching urls and saved it on my disk.
import xray from 'x-ray';
let x = xray();
const targetUrl = 'https://en.wikipedia.org/wiki/Category:Marvel_Comics_superheroes';
const selector = '#mw-pages .mw-category-group li a@href';
x(targetUrl, selector)((urlList) => {
// urlList is an array of all `href` values
});
Then my journey of extracting data from the Wikipedia begun.
As I said, I love APIs. And the Wikipedia being the huge project that it is, I was sure that they had an API to get clean data from each page. They do have an API for sure, but it only returns the raw dump of the page, including a mix of HTML and custom Wikipedia markup. This is not formatted at all, so was of no use to me.

Example taken from here
DBPedia
I kept searching and found the DBPedia, which is an unofficial project of creating an API of structured data on top of the original API. The people in this project did an Herculean job of converting the raw markup of my previous example into nice looking JSON responses.
{
"abstract": [
{
"lang": "en",
"value": "Hercules is a fictional superhero appearing in […]"
}
],
"aliases": [
{
"lang": "en",
"value": "The Prince of Power, The Lion of Olympus, Harry Cleese, Victor Tegler"
}
]
}
Taken from here
Unfortunately, the DBPedia is not dynamic, and all the data returned by the API is frozen in time. Frozen on August 2015 to be exact. It means that all recent development in the Marvel universe where no taken into account. And worse than that, some really popular characters did not even had any data attached to them.
Infoboxes
That's about that time that I realized that the only information that I actually needed was the one displayed in the infobox. The infobox is this little white box on the right side of any Wikipedia page that displays an overview of the most important facts of the page. In my case it was the name of the character, its potential aliases, powers, known teams and authors.
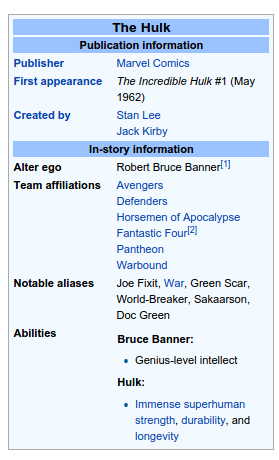
I did not really care about the rest of the page. What I had in mind for my demo would be a simple way to search through all characters and filter them based on exactly those criteria (power, teams, authors) and being able to find them with any of their aliases. So I needed a way to extract content from the infobox.
Fortunately, I started this project in node. And node comes with npm, where there is a module for anything. I quickly found wiki-infobox that let me extract a mostly structured representation of the data in the infobox, by just feeding it the name of the page.
import infobox from 'wiki-infobox';
infobox('Hulk_(comics)', 'en', (err, data) => {
// {
// "character_name": {
// "type": "text",
// "value": "The Incredible Hulk"
// },
// "aliases": [
// {
// "type": "text",
// "value": "<br>Green Scar<br>World-Breaker<br>Jade Giant"
// },
// […]
// ],
// […]
// }
});
I say mostly because the module tries its best to manually parse the raw dump I showed earlier. And it did that using regexp and trying to handle all possible edge cases. Overall it worked quite well, but I still had to clean the output to have something that I could work with. My respect for the team behind DBPedia grew even more at that time, because extracting formatted data from the initial dump is clearly not an easy task.
Using both DBPedia and the data I got from my infoboxes, I started to have an interesting dataset. One thing that was missing were popularity metrics. I wanted my heroes to be displayed by order of popularity. If I start typing iron, I want Iron Man to be displayed first, not the unknown Iron Monger character.
Wikidata
In order to get this information, I tried the Wikidata API. This API gave me a lot of metadata information about each Wikipedia page. But that's it, only metadata. Data about the data. Like the name of each page in each language or the other names that redirect to the same page. This wasn't exactly what I was looking for, but let me grab a nice list of aliases for my characters. Thanks to that data, I could now find Spider-Man with Peter Parker, Spidey or Webhead.
Of course, there's an npm module to do that easily as well: wikidata-sdk.
Page views
The more I searched for Wikipedia-related APIs, the more I found weird projects. The last one I used is stats.grok.se, which is the personal project of a core contributor that exposes as an API, the pageview count of each Wikipedia article on the past 90 days. This could give me the popularity ranking I was looking for. The page for Iron Man was visited way more often than the one for Iron Monger, so I could use that data to rank them.

Unfortunately, the stats are only valid up to December 2015. After that, the endpoints were just returning empty results. But what I also discovered is that those results were Netflix-biased. I mean that at the time I did the crawling, Netflix just released its Jessica Jones show, so Jessica Jones and all the other characters from the show (Purple Man or Luke Cage) had the more important number of pageviews. While the show is great, Jessica Jones is in no way a more popular character than, say, Spider-Man, Iron Man or Captain America in the comics.
My dataset was starting to look promising but there was one information that I still did not manage to get. Believe me or not, but from all the APIs I tried, absolutely none of them were able to give me the url of the image used to display the character. I absolutely needed this image to build a demo that looked nice, so I coded another small x-ray script to go scrap every Wikipedia HTML page and extract the image url. Sometimes the best solution is the more obvious one.
Marvel API
It took me a few days to do everything I mentioned above. Just to be sure, I had a new look at the Marvel developer portal and I discovered that they fixed it. So I registered for an API key and started exploring their API to see what I could extract from it.
First thing to know is that the Marvel API is tedious to use. I had countless timeouts, infinite redirect loops, empty results, errors and other things that made the whole experience unpleasant. But in the end it was all worth it because of the quality of the data you can extract from the API.

First of all, they do provide url to an avatar image of each hero. And not just any avatar image, one that is correctly cropped and with all background noise removed. It also gives you an in-universe description of each character. So now I could display that Daredevil was the secret identity of Matt Murdock, whose father was a boxer. As opposed to simply saying that "Daredevil is a fictional character from the Marvel universe", which is not very relevant. And finally the API gave me the popularity ranking I was looking for. For each character I have the count of comics, stories and events they were involved in.
{
"name": "Daredevil",
"description": "Abandoned by his mother, Matt Murdock was raised […]",
"thumbnail": "http://i.annihil.us/u/prod/marvel/i/mg/6/90/537ba6d49472b/standard_xlarge.jpg"
"comicCount": 827,
"eventCount": 11,
"serieCount": 163,
"storyCount": 1326
}
All data I could get from the Marvel API was of much better quality than anything I could have had from the Wikipedia. Still, each character only had a few bits of information, so I merged results with my previous Wikipedia scraping, using fallbacks to always use the best possible value.
Marvel website
One last drawback of the Marvel API is that their website does not even use it. You can find on the official Marvel website pages for each character that display more information about them that what you could find in the API (things like their weight or height). The designers at Marvel did an incredible job at defining a main page color for each character. It means that the Hulk page will have a green tint, while it will be purple for Hawkeye and red for Daredevil.
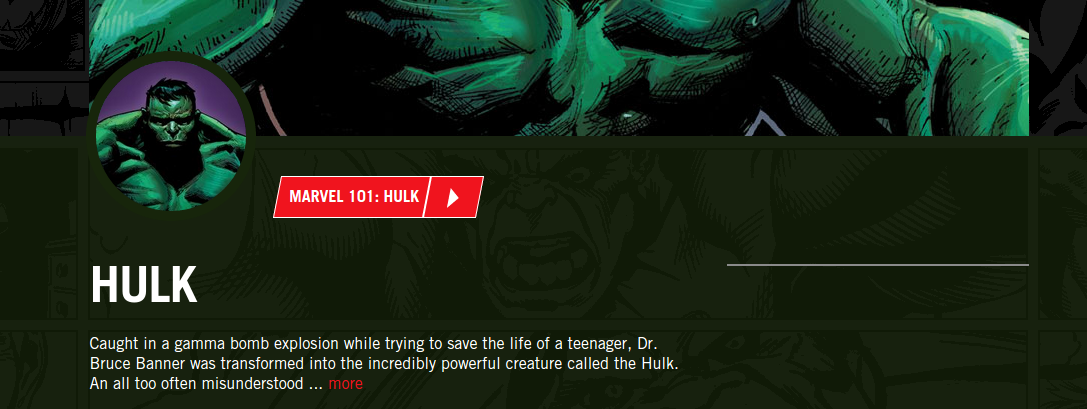
They also defined custom background images for major characters. All character pages have several panels of comics in the background, but for major characters, all panels are actually taken from real adventures of that character.
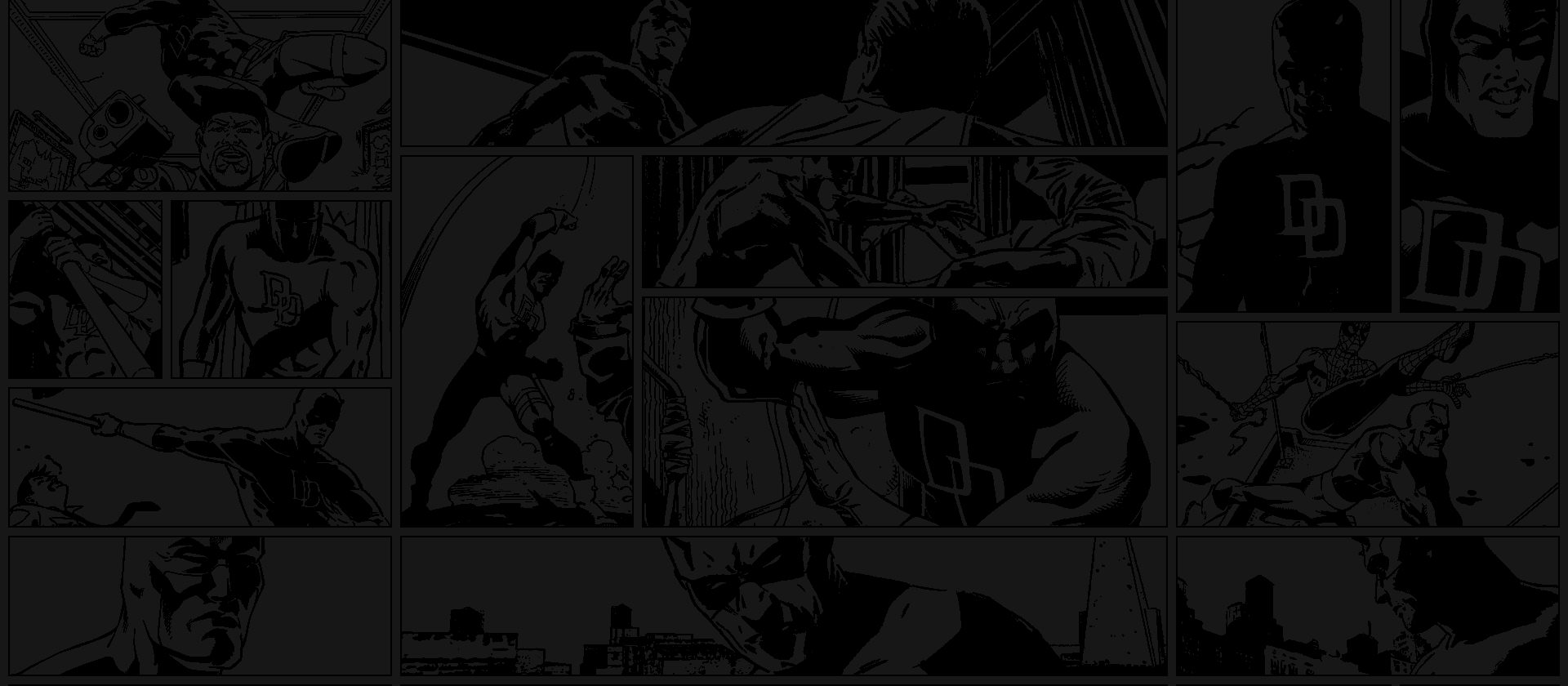
Through tedious scraping and parsing of CSS and JavaScript, I managed to extract this information for each character, and could use it to improve the UI.
Tips & tricks
I will give more details about how I build the UI in another post, and don't worry it will be way easier than getting the data. Before closing this post I'd like to share a few tips I learned from this whole process of getting data out of APIs and websites.
First of all, you should create isolated and repeatable scripts. In my case my data was coming from various sources, so I created a script per source. That way I could just run the DBPedia script again and update only the data coming from the DBPedia.
Crawling always comes in two steps. First you have to get the data from the website or API, then you have to extract and format it the way you want.
Downloading data from an endpoint is as easy as saving the distant url on disk, but this can take a long time because you have to pay the price of the whole download process. On the other end, once you have the file on disk, parsing it to format its content the way you want it is really fast, but chances are that you'll have to rewrite your script dozens of times until you got all the edge cases right.
My advice is to always create two different scripts. The first one will blindly download all the urls and save the output on disk, without doing any formatting on it. The second one will read the local version and extract the data. Doing so, you only pay the price of the download once, and can then quickly iterate on the extraction part.
I would not commit the temporary files into a git repository, but only the output formatted files. Whatever the format in which you store the output file, I would make sure that the way it is saved is consistent across extractions, so you can easily do a diff between two versions of the file. For JSON, this means ordering your keys alphabetically.
Finally, when dealing with external sources, especially the Wikipedia, I'd be extremely careful on the inputs. You're basically handling data that has been written by somebody else. Chances are that they forgot to close a tag, or that the data will not be correctly formed one way or another. Add scripts to fix the data for you, and add tests to those scripts so you're sure that when fixing one issue you're not creating a new one. I have more than 300 tests for this example. It's a lot, but it's needed.
Conclusion
This was a really cool project to do. You can see the demo online, or browse through the code. Everything is in it, from the import scripts to the final UI, even including the JSON data files.
Want to add something ? Feel free to get in touch on Bluesky : @pixelastic.bsky.social