Searching the ParisWeb conferences
05 Sep 2016I've been going to ParisWeb almost every year since it started ten years ago. I missed the first one and the 2012 edition (I was living in New Zealand at that time. I guess it's a good enough excuse).
I cannot say how much I learned from this event. I used to say that I could learn more in two days at ParisWeb than in 6 months of technical watch on my own, reading blogs. That's the conference that made me the web developer I am today. It has this incredible energy, this special #sharethelove mood.
This year I wanted to give something back to the community, so I built a little page to let you search through all the talks of the last 10 years. I hope to make access to those little gems of knowledge easier for everyone.
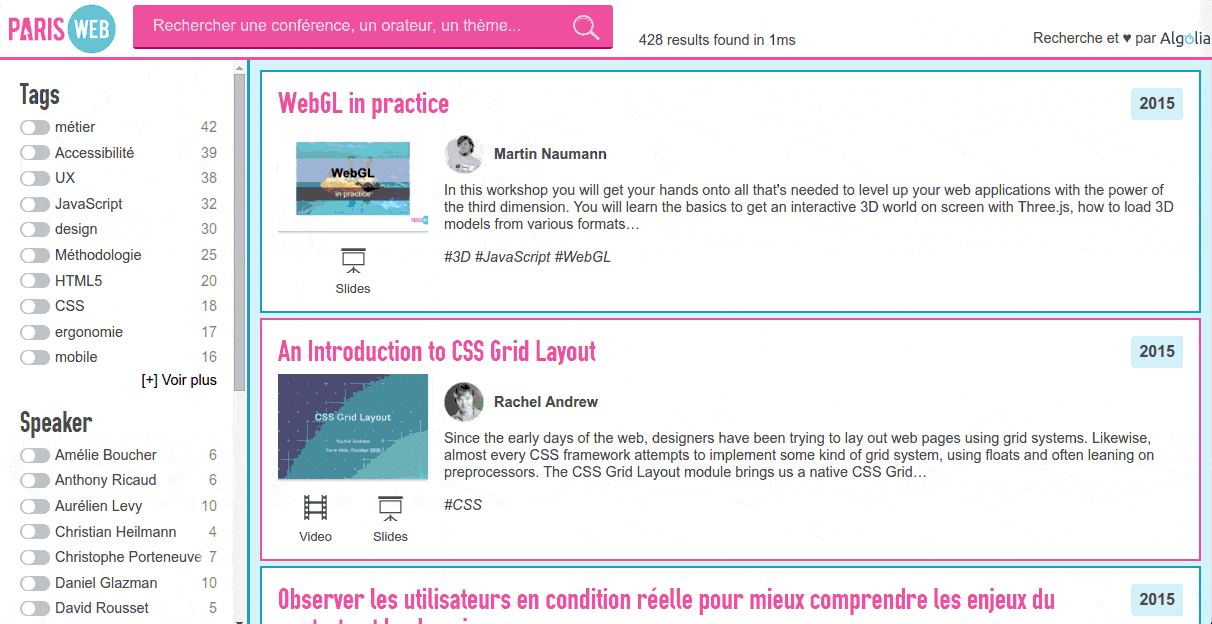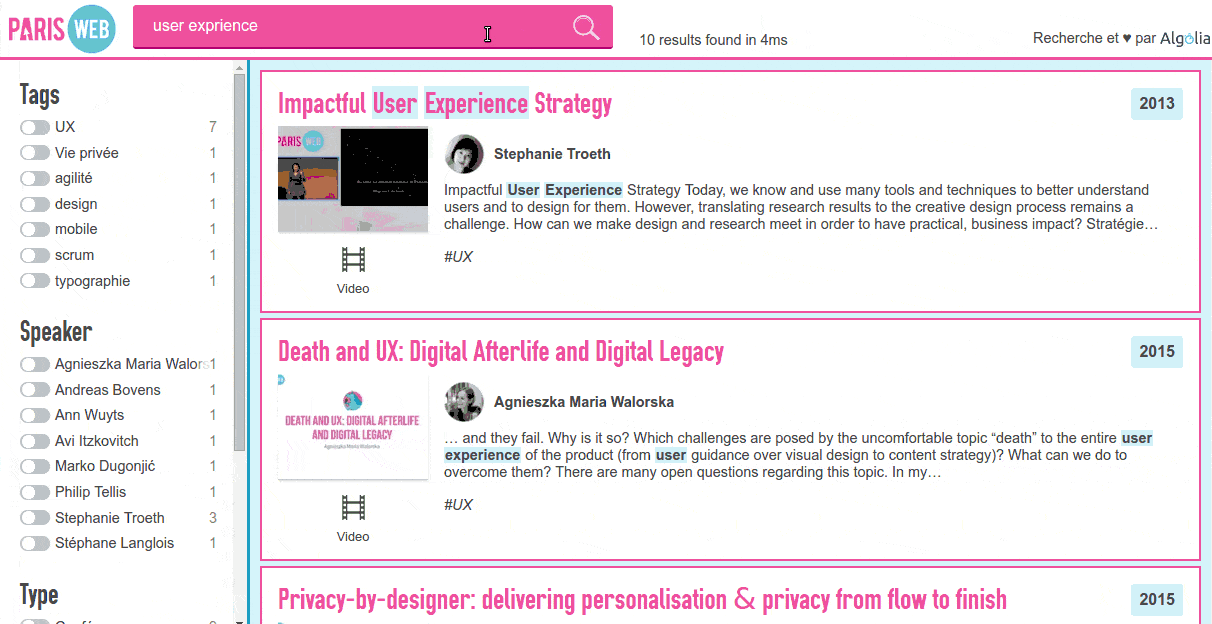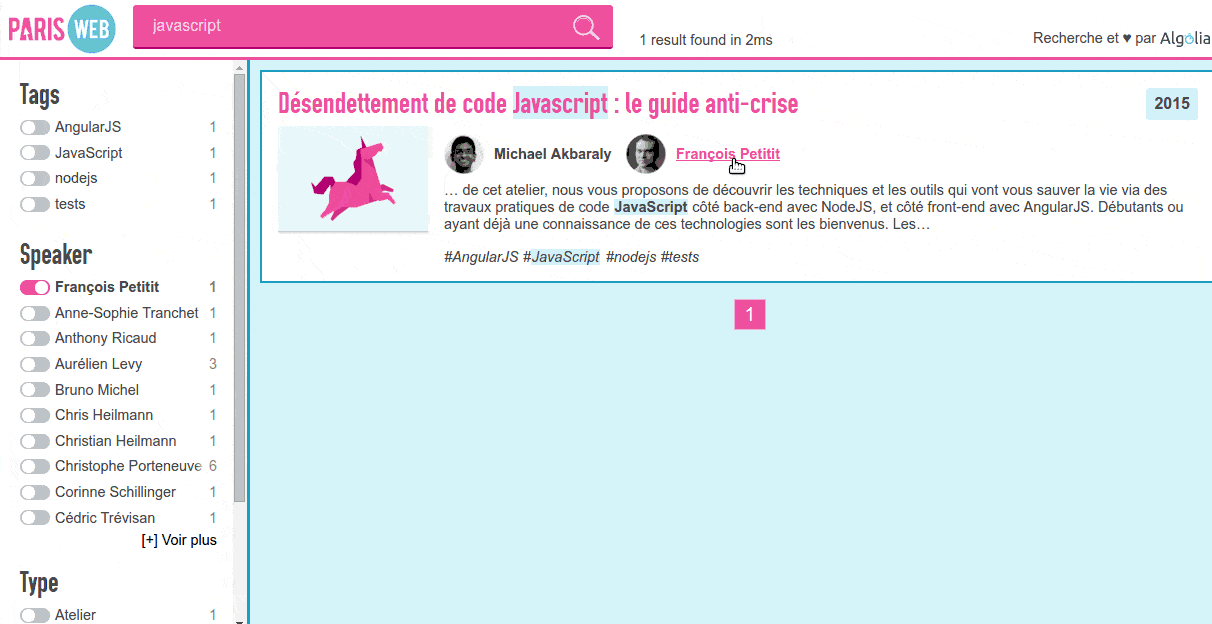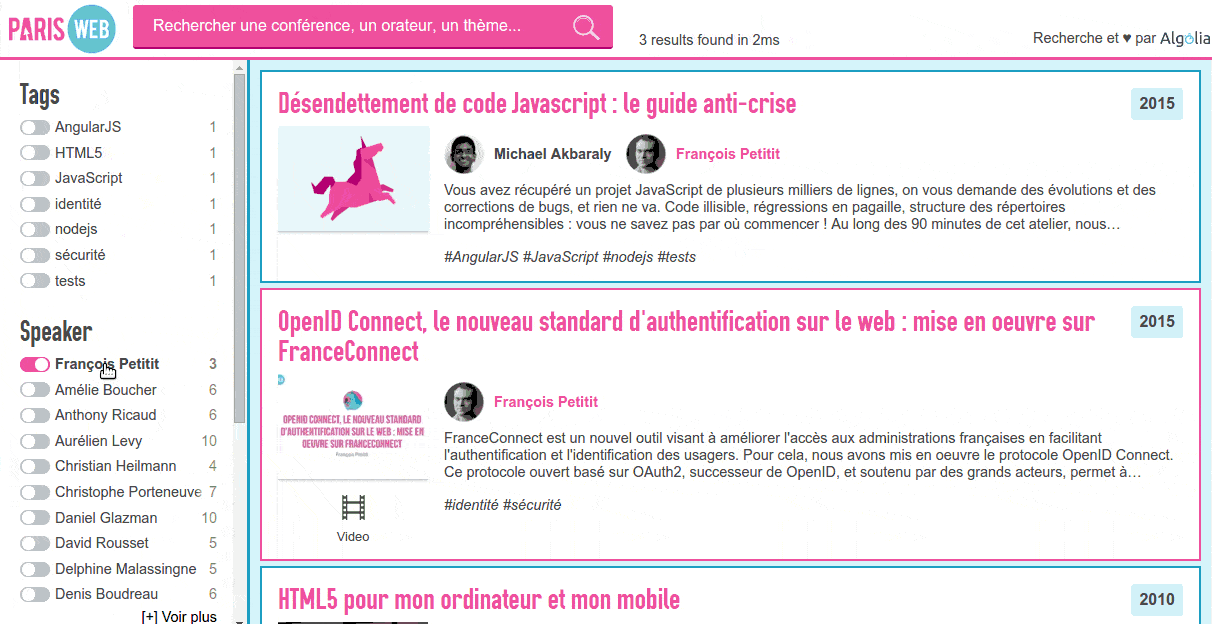
As a project is only finished once it's documented, let's see how this was done.
I work at Algolia, the company that provides the underlying search engine. I'm familiar with this kind of projects, but I did not use any special Algolia treatment and everything I built has been done with open-source tools and free accounts.
Getting the data
The first part of every search project is to get the data you want to search. It is the longest part of the job. A handful of websites expose useful data through an easy-to-parse API. Most of the time you have to manually crawl the website and extract the interesting bits through HTML parsing.
ParisWeb was no exception, but the staff did an amazing job of keeping online all the previous versions of the website. I manually downloaded all the program pages on my disk and run ruby scripts on them to extract basic information from all the talks. I used Nokogiri, the de facto gem for HTML parsing.
This first pass let me get basic information about each talk: title, authors and description. I then had to add the relevant slides and video urls to each talk (when available). Thoses are listed in another page, so I had to do another HTML parsing and merge the results together. This part of the code contains some specific and ugly rules.
Unfortunately for me, the website changed almost every year so I had to write a different version of the script for each year. My scripts looked more and more like hacks, with copy-pasted methods from one script to another. I could have done it better, but as they were supposed to be run once to generate the list, I figured I could live with that.
Adding thumbnails
I knew I wanted to add thumbnails to the results, because full-text results are boring. I decided that using the slides thumbnails would have more impact, with a fallback to the video thumbnail.
ParisWeb videos are hosted either on DailyMotion or Vimeo. Getting thumbnails from DailyMotion is a breeze because you can guess the thumbnail url as soon as you know the video id. Getting thumbnails from Vimeo on the other hand involve a call to their API.
For the PDF thumbnails, I first searched for an online API that would be able to do that for me, but could not find anything. So I started downloading all the PDF talks, extract their first page and convert them to png.
I wrapped this all into one script that will build a big array of all the talks, adding links to thumbnails to each. The final JSON is available here if you want to build something else out of it.
Configuring the search
I wrote another script to push the JSON file to the Algolia API and configure the index. I wanted it to search into the talk title, the authors name, tags and talk description, in that order. I also added filters (what we call facets) on the authors, tags and year as well as defining synonyms (like js/javascript or ux/user experience).
Building the front-end
The layout of the final page is a classical layout of search pages. A header on top with the search input, a sidebar on the left for filtering and the main area on the right. I re-used part of the code I already did for the Marvel Super-Search.
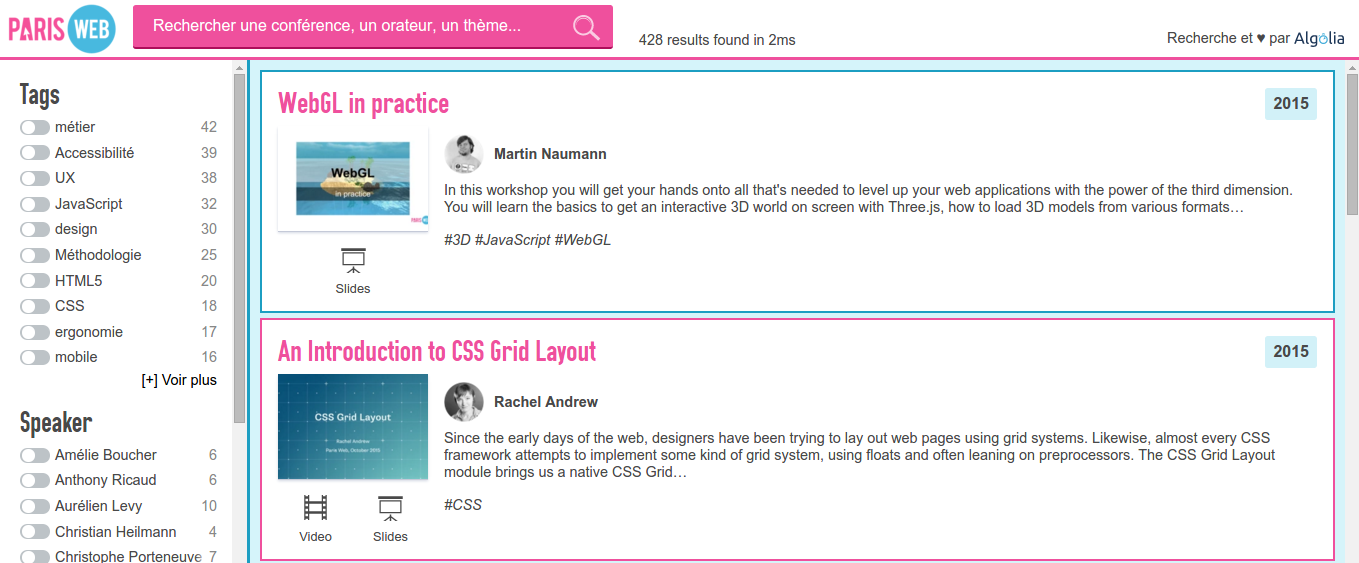
I used our instantsearch.js library. I started by creating the HTML markup, using empty divs as placeholder for where I wanted the various elements of the search: input, filters, results, etc.
Then, I instanciated instantsearch with my Algolia credentials and configured the widgets (defining if I wanted an AND or a OR on the filters, how many to display, etc). I also created a Mustache template for results and styled all that with the ParisWeb colors.
I used Cloudinary as a CDN for the images, which let me resize, compress and cache them on the fly. I also forced all author pictures into grayscale for a better visual harmony.
Getting feedback
As I was building it, I often pushed the site online (hosting it on GitHub pages), to get feedback from some beta users. It gave me a lot of interesting ideas and allowed me to improve it as I was building it.
I'm still eager to know what you think about it, and hope it will be helpful to you. If you find any issue or would like to suggest an improvement, feel free to add it to the issue tracker.
Want to add something ? Feel free to get in touch on Bluesky : @pixelastic.bsky.social