02 Jan 2025When working with Airtable, I've started to develop some good practices regarding IDs in my tables.
Airtable has a concept of a Primary Field, which is the "main" field of a given entry, displayed as the first column in Grid view. It can be any field of the table (even a formula aggregating several fields), and will be used in the UI to represent the row.
But Airtable also has an internal notion of a RECORD_ID() (a string like recR5nCNhl3SHbC1z). It's an internal ID, and if you're only using the Airtable UI, you'll never see them.
But the moment you start using the API, it's everywhere, as it's the canonical way to identify a record.
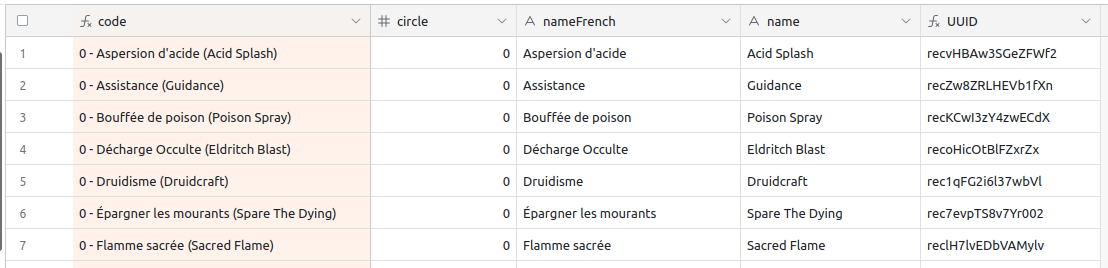
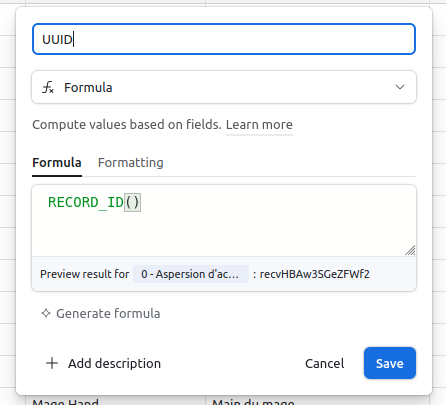
I developed the habit of making the RECORD_ID() visible in all my tables. The first thing I do when I create a new table, is to add a field called UUID, set it as a formula, with a value of RECORD_ID(). That way, I have an easier mental mapping between what I can see in the UI and what I interact with in the API.
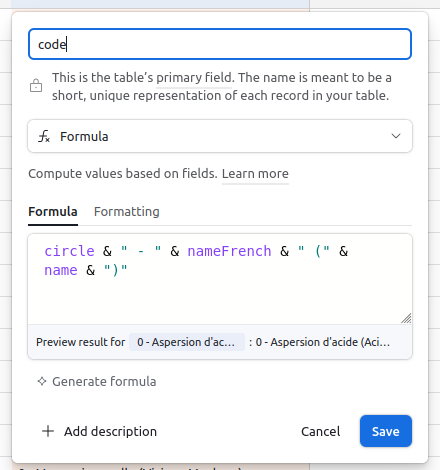
I also tend to name my Primary Field code, and make it a concatenation of unique (but short) identifiers of my record. That way, I can easily identify them, sort them, etc. I never use that field anywhere but in the UI.
Coming from a dev background, not understanding the difference between the visible Primary Field and the hidden RECORD_ID() has been one of the first things that tripped me up when I started plugging Airtable with Make. Having the UUID clearly exposed in the UI and the record makes everything way simpler.
31 Dec 2024I’ve been saying, “I’ve been coding for over ten years.” for more than a decade now (so yeah, I've been coding for a long time). And I still love it.
Coding feels like a deeply creative process to me. It’s about long-term problem-solving and crafting elegant solutions. But it's also about diving into the nitty-gritty and getting your hands dirty. I take pride in writing clean, maintainable code, but also in finding a clever hack to glue everything together.
The one thing that I never found fun are the repetitive tasks. They’re fun the first time but quickly become tedious after the tenth. I think that's for hat reason that I’ve always been fascinated by automation. Recently, after attending the dotAI conference, I saw the incredible potential of AI and automation tools, which pulled me into yet another rabbit hole.
Make is the new Zapier
Of course, I've already automated most of my code-oriented tasks, using tools like CircleCI or Netlify/Vercel/Cloudflare functions. Those tools are great, but they fall short when the task to automate requires some UI (like getting data from a website, automatically downloading invoices from your emails, etc).
For those tasks, I had tried tools like IFTTT and Zapier in the past. I found IFTTT a genius idea the first time I used it, but its functionality was quite limited. Zapier, while more advanced, felt similar and quickly became prohibitively expensive. So, I came back once again to my custom bash and JavaScript scripts.
But then, Make happened. I gave it a try and it has completely changed how I approach automation. Make combines the best of IFTTT and Zapier with a much more intuitive UI, powerful debugging tools, and is way cheaper. It’s incredibly versatile, allowing me to complete projects in an afternoon that I’d postponed for years. Every day, I experience "wow" moments as I connect this API and that API to automate stuff I didn't think I could automate. Make feels like a superpower, I'm feeling that exhilarating feeling of "I can do anything!" just like the first time I started coding.
More wow effects
If Make can replace much of my need for scripting, Airtable has given me a similar “wow” effect for data management. Airtable is an incredibly powerful database with a clean UI that makes it easy to view, edit, and manipulate data visually. I can create formulas, so one field is derived from another, link tables together, upload files directly in tables, build visual custom interfaces to show specific data. Everything is of course accessible through the API... and through Make; double "wow" effect!
And then you can even plug ChatGPT in Make, to enrich data you have in Airtable, and dynamically transform it. Triple "wow" effect. And since I've started to discover this strange new world of "no-code automation", I'm discovering more and more of those awesome tools every day. I keep being amazed at how powerful and accessible they’ve become.
Posting more here
I started this blog many years ago, when I started to learn web development, and I used it as a platform to share what I learned. I think it's only fitting if today, I use what I learn in the realm of no-code automation to post more here, and post more about what I learn, and use what I learn to post more.
I know I have ideas worth sharing. My thought process is that if I, after 20 years of experience, am still learning new things, I'm sure others can learn from them too. This blog is a modest platform, but it’s a way to connect with you, readers, and contribute to the pool of shared knowledge. Just as my coding skills allowed me to build and customize this site many years ago, I hope my growing expertise in automation will help me bring more meaningful content to it.
Hope to see you soon, once I've posted more!
31 Oct 2024As a web and software developer, I often see coding as a creative way to solve problems. After years in the field, I take pride in writing clean, understandable, and maintainable code. Understanding the quality of my work gives me satisfaction, much like an artisan. Recently, I have been diving into automation tools that help streamline repetitive tasks, enhancing my productivity.
My journey with automation tools started with IFTTT, which I found quite useful but limited in functionality. Zapier was a step up, but it’s pricey for what it offers. Then I stumbled upon Make. This platform provides many features at a lower cost, allowing me to work faster. Even with some quirks, the speed and ease of development I gain from Make give me a "wow effect" that would have taken years to achieve otherwise.
Integrating tools like ChatGPT and Airtable has changed how I manage information. ChatGPT, as an API, allows me to manipulate data easily. Airtable acts as my source of truth, offering a user-friendly graphic interface and flexible views for managing data. Notion complements this by providing a smooth note-taking experience, especially with its new API. Working with these tools is not just efficient; it feels empowering.
I also find myself wanting to share what I learn. As a public-speaking trainer, I hear many interesting topics and wish to help others communicate their ideas effectively. I often think about the time I spend solving problems; sometimes I learn concepts that, if I could explain simply, would benefit others. However, creating an article or preparing a talk takes time I often don’t have.
To bridge this gap, I've embarked on a project to automate how I turn raw ideas into polished content. Through voice notes, I can quickly express my thoughts, and I want to transform these unstructured ideas into useful formats like articles or conference talks. The thought is to create a system that organizes and refines my notes, making it easier to share knowledge.
This process of transforming spoken ideas into written content involves leveraging AI tools that can help refine and structure my raw notes. I imagine a comprehensive database where I store these ideas, making the content creation process easier and faster. The audio notes I take can serve as the seed from which various media, such as blog posts or presentations, can grow.
In fact, this blog post is an example of what I’m trying to achieve. It all began with a simple audio note I recorded on my phone. By analyzing and refining that five-minute monologue, I've created something that I hope is engaging and useful to you. This journey of integrating automation and AI into my workflow has only begun, and I look forward to sharing more about this exploration as it evolves.
Disclaimer: This blog post hasn't been written by me. I recorded an audio note of what I wanted to say, then built an automation process (using the tools I mention) to generate the final blogpost. The ideas are mine, the way it's written is not. It's not good enough (I feel), but is a good start.
19 Dec 2023zsh has a lot of variable modifiers, and sometimes trying to put more than one on the same variable either throws an error or does nothing.
To fix that, I've been assigning and re-assigning to the same variable, each time with a new modifier added.
Today, I found a syntax that allows chaining/embedding of modifiers.
local myArray=(../../up-the-tree ./here ../in-the-parent)
# To display this array from the closest to the furthest, here is what I used to
do
myArray=(${(O)myArray}) # To sort it in reverse order
echo ${(F)myArray}) # To display it line by line
The following syntax also works:
07 Apr 2023To pad a string with leading spaces in zs, you can use ${(r(15)( ))variableName).
r(15) pads on the right (use l for left padding)- The
15 defines the maximum length of the string ( ) defines the character to use for padding (here, a