I wanted to write a recap of this session for a long time. I'm in a flight trip above the Atlantic ocean, so I have a bit of time in front of me. Let's get started.
Introduction
One of the most valuable learnings from my previous company was the public speaking course I attended (thanks again Marc). With two days of training I went from "Speaking in public? Are you kidding me? I'll NEVER do that, that is way too scary" to "Speaking in public? Sure, I love that, I have a lot to share!".
Let's see if I can write down here everything that class taught me. It might be a bit rough, but this is basically a rewriting of my notes at that time.
The class was about what people see when they see you speaking publicly. We did not go into what is happening inside, because it is too intimate, we focused on what was visible on the outside.
We were asked to tell how we thought our public speaking skill was. What scared us, what we thought we do well, etc. I said that if I know the subject I'm talking about, I think I can handle the situation well. If I have a complex set of ideas to share I might get confused and forgot important details. I also know that I speak fast, so I need to be careful. Also, I've been game-mastering fantasy roleplay for more that 15 years, so I know a bit about improvisation. I'm also scared of how to start a talk, when everybody is talking among themselves.
Basic principles
We were taught the 4 most important rules:
We need to stay natural. This is not a theater play, and we are not playing characters, we are ourselves. We do not have to show everything, only what we want to show.
We must remember that this is nothing personal. You do not go on stage to be loved. You go on stage because you have something to share. People care about what you say, not who you are.
We should not listen to that little voice in a corner of our head that repeats "you'll never be able to do it", "what you say is not interesting", "they already know all I can say".
The speaker is the only accountable person. The listeners are always right. If they did not understand something it's not because they are foolish, it's because you did not explain it well enough.
Public speaking is not only about speaking. Oral speaking is just a small part of it. Your whole body is expressing your ideas when you are on stage. We are trying to convince people of what we are saying, and we do that by more than words. We do that by being convinced ourselves and our whole body will show it, in the way we breath, the way we walk, the way we move, etc.
Conversation, Information or Communication
We also made a clear distinction between a conversation, an information and a communication.
A conversation is mundane and informal. It's small-talk and there is no definite point. It can happen anywhere, anytime, there is no specific pattern.
An information is formal. It goes one way, from the one who knows to the one who does not know. The boundaries are clear. Think of the flight speech about exits in planes.
The goal of a communication is to say something and that the other party understands it. It is meant to have an impact. It is part what I say, part how I say it, part who I am and part how I am linked to what I say. It's content, form, behavior and relationship.
Make your message clear
You want people to have a before and an after your talk. Because if they don't, what was the point? You must have a message they will remember.
You should be able to pitch that message in one or two short sentences.
Do not hesitate to repeat the message throughout the talk, with different words, but with the same meaning.
Give context to what you say. Give examples, and facts.
People might understand the theory of what you're talking about, but if you give them real examples, they will remember it better once you've finished talking. If it helps the listener understand and remember, you should do it. Remember that the audience is always right. If it's too complex for them, they will stop following.
People have a limited attention span. Maybe you're the first talk of the day and they are not yet fully awake, maybe you're the last talk before lunch and they are hungry, maybe the speaker before you was boring and they are falling asleep, maybe you're the last speaker of the day and they are tired. There are countless ways that the audience will not be in the perfect mood to listen to you. This will not matter if you've adapted your speech so it is really easy to understand.
Split your talk in chunks. Do small breaks. Don't let the audience doze off because of your monotonous voice. Throw an image here and there to wake them up. Make it feel like there is something new to discover at each new slide. Try to hook them. If they are not hooked, they will just go to their smartphones and check Twitter. Talk about you and how you relate to the subject you're talking about.
Now that we've seen generic ideas, we'll go a bit further into the content itself.
Introduction
Keep about 1mn for an introduction. Start by creating a desire, explaining why, sparking curiosity. Giving a real anecdote is nice way to start.
At this point, we were suggested to use sentences like "Have you ever noticed...", "Are you like me and..." or "From the dawn of ages, humankind have..." to quickly rally the audience to what we are going to say. I personally don't want those introduction because they look too much like one-man shows. Also, the talk being unidirectional, the audience cannot answer and if they do not agree they can't do anything but listen, which will frustrate them. So my personal advice is to avoid those over-generic sentences.
You can also clearly define what the audience will learn. Clearly show what you are going to talk about. Don't let people wonder what the next subject will be. Show your table of content right at the start. You can even announce what you conclusion will be right from the introduction. And then dive into the subject wholeheartedly.
Clearly show where you are
Whenever you transition from something to another, from one slide to another or from one idea to another, verbalise it. Say that we're moving to something else, that way people can more easily clear their mental buffer.
If you ever enumerate things, count on your fingers, or clearly show that every item in the list is different. Do not put too much content in your slides. People will read your slides, and while they do, they don't listen to you. So try to keep the information in the slides to a minimum. It should be just enough to let someone see what your current point is and where you are in your explanation.
Add a clear mention of the current chapter you're currently explaining, so people know where you are. Clearly show how many slides you have, so they know when to expect the end of your talk. If they think it is a never ending talk, they will get bored before the actual end.
You are not transparent
Do not confess your internal state to the audience. Do not tell them how stressed you are, do not say "Oh I'm sorry, I don't remember what I wanted to say". Remember that everything that happens inside of you is not visible on the outside. If you tell the audience that you are stressed, then they'll know. If you say nothing, they won't have a clue.
If you don't remember what you want to say next, just leave a blank. When people add silence to their talks, it makes the audience think about what was said before. It is way better to just put a silence than a "hmm, so... Hmm... Yeah". The former makes your previous sentence feel really important while the latter makes you sound foolish.
Own the stage
Try to be sure of what you say, people will feel your presence on stage and will feel like you belong there. This will give you legitimacy.
Be dynamic, don't be static. This show that you have a strong belief in what you say. And people don't want to hear you talking about something for which you don't really care. They already have plenty of things they don't care about, they don't need yours.
Be synthetic. Everybody can talk about any subject, but only the real professionals can be synthetic about it. This is related to the Dunning-Kruger effect, but the more synthetic you are on a subject, the more people will see that you've mastered it. On the other hand if you start explaining every little details, it show that you do not see the big picture.
Conclusion
When it is time to conclude your talk, make it as interesting in the closing than in the opening. Repeat your message one last time, and what the audience can do to activate that message. Ask if people have any questions, and don't forget to smile, we don't like to ask questions to someone with a closed face.
Do not, ever, finish your talk with "I hope you liked it", it undermine everything you said. Instead, say "With everything I talked about, you are now ready to do {whatever you talked about}".
Bonus
We also got a list of mantras that you can repeat before going on stage:
I do not talk because I want to be loved. I talk because I want to be understood.
I know it's normal to be scared when speaking publicly, and I know this is not a weakness.
My internal stress is not visible on the outside. People cannot read inside of me.
If I feel the stress coming up, I slow down, I breath, I take my time.
Bonus number two
We also had a nice discussion about face-to-face talks. For example when you're meeting with customers and you want to explain why something they did is wrong and why your way is better. You want to convince them of your way. Here are a few things to keep in mind:
Never say to the others that they are wrong. Their reasons are perfectly valid, knowing what they know.
Being convinced of being right is not enough, you need to also be convincing.
No-one was ever convinced by an authoritative argument. You have to be reasonable, and nuanced.
Give facts, examples, evidences.
Avoid antagonism. You and them are working toward the same goal: using the best possible solution. Understand their issues, put yourself in their shoes.
Say things clearly, do not make them think they may have not understood things clearly or that you are hiding something.
Last December I discovered that Marvel had an API. Yes, that's right, Marvel, the publisher of all the comics I used to read. I'm a developer, but I'm also an avid consumer of APIs and love to build things with all the available data.
Since I joined Algolia, I'm always looking for nice datasets to build demos with, and to battle test our instantsearch.js library. While Algolia lets you search in any kind of data (as long as you can convert it to JSON), fiddling with a dataset full of superheroes is way funnier than any other dataset.
So I started registering to the Marvel developer program to get an API key and started pulling some data. Or actually that was my original plan, but the developer website was buggy at that time and I could not register at all.
At first I was disappointed because I really wanted to index all these characters and superpowers, but I wasn't going to let that bring me down. I started rolling up my sleeves and went on the hunt for another interesting source of data.
Wikipedia
I obviously quickly ended up on the Wikipedia, where I could find a serie of pages listing all the heroes and villains of the Marvel universe (or actually, universes). I wrote a small node script using x-ray to get the list of names and matching urls and saved it on my disk.
importxrayfrom'x-ray';letx=xray();consttargetUrl='https://en.wikipedia.org/wiki/Category:Marvel_Comics_superheroes';constselector='#mw-pages .mw-category-group li a@href';x(targetUrl,selector)((urlList)=>{// urlList is an array of all `href` values});
Then my journey of extracting data from the Wikipedia begun.
As I said, I love APIs. And the Wikipedia being the huge project that it is, I was sure that they had an API to get clean data from each page. They do have an API for sure, but it only returns the raw dump of the page, including a mix of HTML and custom Wikipedia markup. This is not formatted at all, so was of no use to me.
I kept searching and found the DBPedia, which is an unofficial project of creating an API of structured data on top of the original API. The people in this project did an Herculean job of converting the raw markup of my previous example into nice looking JSON responses.
{"abstract":[{"lang":"en","value":"Hercules is a fictional superhero appearing in […]"}],"aliases":[{"lang":"en","value":"The Prince of Power, The Lion of Olympus, Harry Cleese, Victor Tegler"}]}
Unfortunately, the DBPedia is not dynamic, and all the data returned by the API is frozen in time. Frozen on August 2015 to be exact. It means that all recent development in the Marvel universe where no taken into account. And worse than that, some really popular characters did not even had any data attached to them.
Infoboxes
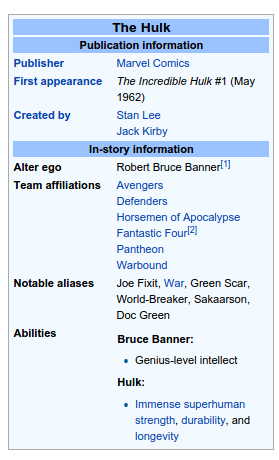
That's about that time that I realized that the only information that I actually needed was the one displayed in the infobox. The infobox is this little white box on the right side of any Wikipedia page that displays an overview of the most important facts of the page. In my case it was the name of the character, its potential aliases, powers, known teams and authors.
I did not really care about the rest of the page. What I had in mind for my demo would be a simple way to search through all characters and filter them based on exactly those criteria (power, teams, authors) and being able to find them with any of their aliases. So I needed a way to extract content from the infobox.
Fortunately, I started this project in node. And node comes with npm, where there is a module for anything. I quickly found wiki-infobox that let me extract a mostly structured representation of the data in the infobox, by just feeding it the name of the page.
I say mostly because the module tries its best to manually parse the raw dump I showed earlier. And it did that using regexp and trying to handle all possible edge cases. Overall it worked quite well, but I still had to clean the output to have something that I could work with. My respect for the team behind DBPedia grew even more at that time, because extracting formatted data from the initial dump is clearly not an easy task.
Using both DBPedia and the data I got from my infoboxes, I started to have an interesting dataset. One thing that was missing were popularity metrics. I wanted my heroes to be displayed by order of popularity. If I start typing iron, I want Iron Man to be displayed first, not the unknown Iron Monger character.
Wikidata
In order to get this information, I tried the Wikidata API. This API gave me a lot of metadata information about each Wikipedia page. But that's it, only metadata. Data about the data. Like the name of each page in each language or the other names that redirect to the same page. This wasn't exactly what I was looking for, but let me grab a nice list of aliases for my characters. Thanks to that data, I could now find Spider-Man with Peter Parker, Spidey or Webhead.
Of course, there's an npm module to do that easily as well: wikidata-sdk.
Page views
The more I searched for Wikipedia-related APIs, the more I found weird projects. The last one I used is stats.grok.se, which is the personal project of a core contributor that exposes as an API, the pageview count of each Wikipedia article on the past 90 days. This could give me the popularity ranking I was looking for. The page for Iron Man was visited way more often than the one for Iron Monger, so I could use that data to rank them.
Unfortunately, the stats are only valid up to December 2015. After that, the endpoints were just returning empty results. But what I also discovered is that those results were Netflix-biased. I mean that at the time I did the crawling, Netflix just released its Jessica Jones show, so Jessica Jones and all the other characters from the show (Purple Man or Luke Cage) had the more important number of pageviews. While the show is great, Jessica Jones is in no way a more popular character than, say, Spider-Man, Iron Man or Captain America in the comics.
My dataset was starting to look promising but there was one information that I still did not manage to get. Believe me or not, but from all the APIs I tried, absolutely none of them were able to give me the url of the image used to display the character. I absolutely needed this image to build a demo that looked nice, so I coded another small x-ray script to go scrap every Wikipedia HTML page and extract the image url. Sometimes the best solution is the more obvious one.
Marvel API
It took me a few days to do everything I mentioned above. Just to be sure, I had a new look at the Marvel developer portal and I discovered that they fixed it. So I registered for an API key and started exploring their API to see what I could extract from it.
First thing to know is that the Marvel API is tedious to use. I had countless timeouts, infinite redirect loops, empty results, errors and other things that made the whole experience unpleasant. But in the end it was all worth it because of the quality of the data you can extract from the API.
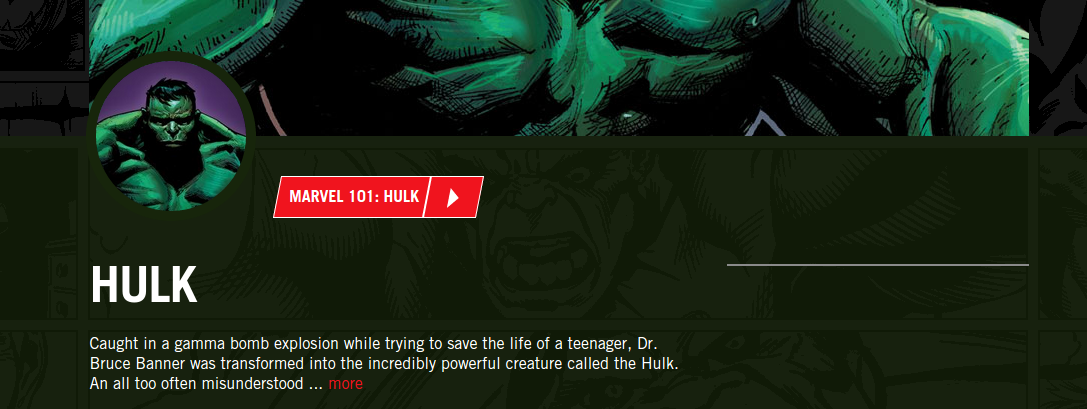
First of all, they do provide url to an avatar image of each hero. And not just any avatar image, one that is correctly cropped and with all background noise removed. It also gives you an in-universe description of each character. So now I could display that Daredevil was the secret identity of Matt Murdock, whose father was a boxer. As opposed to simply saying that "Daredevil is a fictional character from the Marvel universe", which is not very relevant. And finally the API gave me the popularity ranking I was looking for. For each character I have the count of comics, stories and events they were involved in.
{"name":"Daredevil","description":"Abandoned by his mother, Matt Murdock was raised […]","thumbnail":"http://i.annihil.us/u/prod/marvel/i/mg/6/90/537ba6d49472b/standard_xlarge.jpg""comicCount":827,"eventCount":11,"serieCount":163,"storyCount":1326}
All data I could get from the Marvel API was of much better quality than anything I could have had from the Wikipedia. Still, each character only had a few bits of information, so I merged results with my previous Wikipedia scraping, using fallbacks to always use the best possible value.
Marvel website
One last drawback of the Marvel API is that their website does not even use it. You can find on the official Marvel website pages for each character that display more information about them that what you could find in the API (things like their weight or height). The designers at Marvel did an incredible job at defining a main page color for each character. It means that the Hulk page will have a green tint, while it will be purple for Hawkeye and red for Daredevil.
They also defined custom background images for major characters. All character pages have several panels of comics in the background, but for major characters, all panels are actually taken from real adventures of that character.
Through tedious scraping and parsing of CSS and JavaScript, I managed to extract this information for each character, and could use it to improve the UI.
Tips & tricks
I will give more details about how I build the UI in another post, and don't worry it will be way easier than getting the data. Before closing this post I'd like to share a few tips I learned from this whole process of getting data out of APIs and websites.
First of all, you should create isolated and repeatable scripts. In my case my data was coming from various sources, so I created a script per source. That way I could just run the DBPedia script again and update only the data coming from the DBPedia.
Crawling always comes in two steps. First you have to get the data from the website or API, then you have to extract and format it the way you want.
Downloading data from an endpoint is as easy as saving the distant url on disk, but this can take a long time because you have to pay the price of the whole download process. On the other end, once you have the file on disk, parsing it to format its content the way you want it is really fast, but chances are that you'll have to rewrite your script dozens of times until you got all the edge cases right.
My advice is to always create two different scripts. The first one will blindly download all the urls and save the output on disk, without doing any formatting on it. The second one will read the local version and extract the data. Doing so, you only pay the price of the download once, and can then quickly iterate on the extraction part.
I would not commit the temporary files into a git repository, but only the output formatted files. Whatever the format in which you store the output file, I would make sure that the way it is saved is consistent across extractions, so you can easily do a diff between two versions of the file. For JSON, this means ordering your keys alphabetically.
Finally, when dealing with external sources, especially the Wikipedia, I'd be extremely careful on the inputs. You're basically handling data that has been written by somebody else. Chances are that they forgot to close a tag, or that the data will not be correctly formed one way or another. Add scripts to fix the data for you, and add tests to those scripts so you're sure that when fixing one issue you're not creating a new one. I have more than 300 tests for this example. It's a lot, but it's needed.
Conclusion
This was a really cool project to do. You can see the demo online, or browse through the code. Everything is in it, from the import scripts to the final UI, even including the JSON data files.
For a demo website I just built I needed a set of fake user profiles. I needed something with names, address and a profile picture. I didn't want to use any data from real existing people, but still needed something the looked real enough.
So I got a sample of fake profiles from randomuser.me, making sure that no two profiles had the same picture. I also added in the mix a few pictures from my coworkers at Algolia as an easter egg.
Everything is pushed to GitHub, along with the scripts used to generate the data. Everytime you launch the script, it will generate a new list of random profiles.
Here is a sample of what a fake user looks like:
{"email":"liam.walters@example.com","gender":"male","phone_number":"0438-376-652","birthdate":826530877,"location":{"street":"9156 dogwood ave","city":"devonport","state":"australian capital territory","postcode":7374},"username":"biglion964","password":"training","first_name":"liam","last_name":"walters","title":"mr","picture":"men/50.jpg"}
And the full dataset can be downloaded from GitHub as well, and all pictures referenced in the list are also available in the repo.
Maintaining a Jekyll plugin that must work for two major versions of Jekyll is a challenge.
I released the Jekyll Algolia plugin for Jekyll 2.5 (the version used by GitHub). Jekyll recently released their v3.0 and while the plugin is still working, it produces a huge number of deprecation warnings.
This is caused by the fact that Jekyll changed the place where some information were stored (at the root of an objet or in a sub data key). This was mostly a really easy fix to add but I wanted to make sure I wasn't adding any regression as well.
Testing multiple versions
That's when my journey into testing the plugin for two different major version began. I needed a way to launch my tests for Jekyll 2.5 as well Jekyll 3.0 and check that everything was green.
I used Appraisal, a wonderful tool by Thoughtbot. It lets you define your Gemfile like usual, but also named overrides on top of it.
As you can see, I simply defined my dependencies in Gemfile, then override them in Appraisal, naming each group. jekyll-v2 will use Jekyll 2.5 while jekyll-v3 will use 3.0. Jekyll 3 no longer comes shipped with jekyll-paginate so I had to manually add it as well.
Once this is done, be sure to run appraisal install after the usual bundle install. This will create all the needed gemfiles in ./gemfiles.
Running scripts in one version or the other is now as simple as prefixing the command with appraisal jekyll-v2 or appraisal jekyll-v3. Granted, with bundler and rake you end up typing stuff like appraisal jekyll-v3 bundle exec rake spec, but just put it all in a wrapper bash script and problem solved.
This is actually the content of some of my scripts in ./scripts:
I had a couple of tests that made sense only for Jekyll 3, so I had to find a way to only execute them when the Jekyll loaded as a dependency was > 3.0.
Here is the little ruby method I added to my spec helpers:
Gem::Version comes bundled with all the semver comparison you might need, so better to use it than coding it myself.
And an example of how I use it in the tests:
ifrestrict_jekyll_version(more_than: '3.0')describe'Jekyll > 3.0'doit'should not throw any deprecation warnings'do# Given# Whenpost_file.metadata# Expectexpect(@logger).to_nothave_received(:warn)endendend
Using it with Guard
This gem is even compatible with Guard. You do not have to change anything to your Guardfile, but simply prefix your guard call with appraisal like for bundler.
It took me way more time to configure the testing environment for multiple Jekyll version than "fixing" the initial bug. But in the end I'm now sure I won't cause any regression in one version when I fix a bug in another.
Everything is tested on Travis on all supported Jekyll and Ruby versions.
In a previous job, I did a lot of code reviews with a team of more junior developers. My job was to help them write better, more readable and more maintainable code. There was something that came back really often in my reviews: simplifying the if flow.
I'll give you a code example, along with the modifications I suggested to it.
Note that the code is not the real code of the app, but one crafted for the needs of this blog post.
What does it do? It is a (simplified) form validation method. Given an age, gender, firstName, lastName and possibly maidenName, it checks if the form is valid.
The rules are:
firstName and lastName are mandatory fields.
If you're a woman, maidenName is then also mandatory.
The form is always valid if you're older than 50.
As it is currently written, the code works, but it is very verbose and not straightforward. Let's rewrite it.
Remove useless else
The more branching a code has, the more difficult it is to visualize in your mind. Bugs will sneak in more easily in a code that is hard to understand. As the saying goes: the less code you have, the less bugs you can have.
The first step I usually take is to remove all the cruft. The elses in this code are useless. Every preceding if does a return, so if the code goes inside that branching, the whole method would stop. The else is then useless and only adds noise.
What we have now is a simple test to see if the user is under 50 at the start, where we then test for the two only passing scenarios and return false otherwise. If above 50, we always return true.
We've changed a complex multi-level deep nesting of if/else into a simple branching and enumerations of valid cases. This is easier to grasp.
Return early, return often
But this code is not yet clear enough. I don't like the big if surrounding almost the whole method. What we should do is revert the condition to discard the edge-cases earlier and leave the bulk of the method to test the common cases.
In the first lines of the method, we check for the easy validations, the one that can fit in one line and return quickly. This lets our mind quickly discard all the edge cases, and focus the code on the most common use-cases. This way, we do not have to mentally keep track of all the pending if/else the previous code was creating.
Shorter conditions
The code is getting more readable already, but there are still code duplication that we should avoid. We are testing for inputs.firstName !== '' && inputs.lastName !== '' twice. Let's move that into a carefully named variable.
This change has two benefits. First, the if reads better in plain english if you read it in your mind. This will help further contributors (or even you, in 6 months time) understand what the if is actually testing.
Second, if in the future you decide that only the firstName is mandatory, you'll only have to change the var mandatoryNamesDefined declaration and all your checks will be impacted.
Extracting this check into a variable was easy. The hardest part is correctly naming the variable. If you have trouble finding a nice name for your variable, this might be because you're trying to fit to many checks in one variable. Split it in several and then combine them.
One step further
There is still one change we can add. People can only chose a gender of M or F, so we can even reverse the way checks are made at the end by using the return early, return often rule again and inverting the conditions.
Now the code reads like a bullet point list, much closer to the original spec:
If older than 50, the form is valid.
If firstName and lastName are empty, the form is invalid.
If you're a woman and haven't filled your maidenName, the form is invalid.
All other cases are valid.
Conclusion
Code is like literature. Writing it is really easy, anybody can do it. You just have to learn the basic syntax and here you go. Writing code that reads well is harder, and you have to methodically re-read it several times and remove all the useless parts so the reader mind grasps everything easily.
Think of the next person that will read your code to add a new feature or fix a bug. That next person might well be you. You don't want to spend more time understanding the code than actually fixing it. Make your (future) self a favor, and write code that reads easily.